
Welcome
· One min read

Eve
Robot

// <button id='btn'></button>
const btn = document.querySelector("#btn");
btn.onclick = () => {
const xhr = new XMLHttpRequest();
xhr.onreadystatechange = () => {
if (xhr.readyState === 4 && xhr.status === 200) {
console.log(xhr.response);
}
}
xhr.open('GET', 'http://www.scypurple.com/?name=lore&age=18');
// xhr.open('POST', 'http://www.scypurple.com/')
// 携带body参数,post也有get的两种参数携带方式
// xhr.send({name:'lore', age:18}) // 或者 name=lore&age=18
xhr.send();
}
const express = require("express");
const app = express();
const port = 8080;
app.get('/test', (req, res) => {
const {callback} = req.query;
console.log(callback);
const mine = {name:'lore', age:18};
res.send(`${callback}(${JSON.stringify(mine)})`);
})
app.listen(port, (err) => {
if(!err) {
console.log(`listening at ${port}`);
}
})
<body>
<button id="btn">click me!</button>
<script type="text/javascript">
let btn = document.getElementById("btn");
btn.onclick = () => {
let scriptNode = document.createElement("script");
scriptNode.setAttribute("src", "http://localhost:8080/test?callback=fn");
document.body.appendChild(scriptNode);
window.fn = person => console.log(person);
}
</script>
</body>
app.get('/test', (req, res) => {
res.setHeader('Access-Control-Allow-Origin', 'http://127.0.0.1:5500');
res.send('hello');
})
const ajax = (method,url) => {
return new Promise((res, rej) => {
const xhr = new XMLHttpRequest();
xhr.onreadystatechange = () => {
if (xhr.readyState === 4) {
if (xhr.status === 200) res(xhr.response);
else rej('error');
}
}
xhr.open(method, url);
xhr.send();
})
}
const btn = document.querySelector("#btn")
btn.onclick = () => {
const method = 'GET';
const url = 'http://api.h-camel.com/api?mod=interview&ctr=issues&act=today';
ajax(method, url)
.then(resp => { console.log(resp); return ajax(method, url) })
.then(resp => { console.log(resp); return ajax(method, url) })
.then(resp => console.log(resp))
.catch(err => err.message);
}
btn.onclick = async () => {
const method = 'GET';
const url = 'http://api.h-camel.com/api?mod=interview&ctr=issues&act=today';
try {
const res1 = await ajax(method, url);
console.log(res1)
const res2 = await ajax(method, url);
console.log(res2)
const res3 = await ajax(method, url);
console.log(res3)
}
catch (e) {
console.log(e);
}
}
const anotherAxios = axios.create({
timeout: 2000,
baseURL: 'http://localhost:8080'
})
anotherAxios.get('/post');
import axios from 'axios';
const btn = document.querySelector("#btn")
const ul = document.createElement("ul");
document.body.appendChild(ul);
axios.defaults.baseURL = 'http://localhost:8080'
//axios.interceptors.request.use(config => {xxx; return configChange})
axios.interceptors.response.use(resp => resp.data[0], err => {
alert(err);
return new Promise(() => {});
});
btn.onclick = async () => {
const res = await axios.get('/person', { params: { age: 18 } });
const { name, age } = res
ul.innerHTML = `<li>${name}</li><li>${age}</li>`
}
import axios from 'axios';
const btn = document.querySelector("#btn");
axios.defaults.baseURL = 'http://localhost:8080'
let controller;
axios.interceptors.request.use(config => {
if (controller) controller.abort(); //在底层做了处理 if (!request) return; 如果没有请求 不取消
controller = new AbortController();
config.signal = controller.signal;
return config;
})
axios.interceptors.response.use(resp => resp.data, err => {
//alert(err);
return new Promise(() => {});
});
btn.onclick = async () => {
const res = await axios.get('/test1', {params: {delay: 3000}});
console.log(res);
}
对象 ➡️ 数组
why : 对象缺少数组存在的许多方法,例如 map 和 filter 等。
how:可以使用 Object.entries,然后使用 Object.fromEntries:
Object.entries(obj) 从 obj 获取由键/值对组成的数组。map。Object.fromEntries(array) 方法,将结果转回成对象。what:例如,我们有一个带有价格的对象,并想将它们加倍:
let prices = {
banana: 1,
orange: 2,
meat: 4,
};
let doublePrices = Object.fromEntries(
// 转换为数组,之后使用 map 方法,然后通过 fromEntries 再转回到对象
Object.entries(prices).map(([key, value]) => [key, value * 2])
);
alert(doublePrices.meat); // 8
字符串 ➡️ 数组
let str = "lore";
alert([...str]);//spread语法只适用于可迭代对象
alert(str.split(''));//字符串
alert(Array.from(str));//适用于类数组对象也适用于可迭代对象
function foo() {
console.log(a); // 是词法作用域所以输出 2 而不是 3
}
function bar() {
let a = 3;
}
let a = 2;
bar();
this和词法作用域的查找混合使用是无法实现的,this在任何情况下都不指向函数的词法作用域。作用域无法通过 js 代码访问,它存在域 js 引擎内部this的绑定和函数声明的位置没有任何关系,只取决与函数的调用方式new操作符时被调用的函数prototype属性 const memorize = f => {
const cache = new Map();
return function(...args) {
let key = args.length + args.join(",");
if (cache.has(key)) {
return cache.get(key);
} else {
let result = f.apply(this, args);
cache.set(key, result);
return result;
}
}
}
const factorial = n => (n === 1) ? 1 : n * factorial(n-1);
const f = memorize(function(n){
return n === 1 ? 1 : n * f(n-1);
})
// 120
console.log(memorize(factorial)(5));
console.log(factorial(5));
console.log(f(5));
const people = (function() {
let name = 'lore';
const sayName = () => console.log(name);
return { sayName };
})()
console.log(people.sayName());
prototype在左边变量的_proto_原型链上即可const myInstanceof = (left, right) => {
while(1) {
if (left._proto_ === null) return false;
if (left._proto_ === right.prototype) return true;
left = left._proto_;
}
}
const typeOf = (obj) => '[' + Object.prototype.toString.call(obj).split(" ")[1];
const human = {
species: "human",
saySpecies() {
console.log(this.species);
},
sayName() {
console.log(this.name);
}
};
const player = Object.create(human,{
species: {value: "Gamer" },
playGame:{value:function(){console.log(this.game)}}
})
// or do this
/*
const player = Object.create(human);
player.spcies = 'Gamer';
player.playGame = function(){console.log(this.game)};
*/
const lore = Object.create(player,
{
name:{value: 'lore' },
game:{value:'MONSTER HUNTER'}
})
console.log(lore.playGame());
// 也可以创建create方法
const human = {
species: "human",
create: function(values) {
const instance = Object.create(this);
Object.keys(values).forEach(key => instance[key] = values[key]);
return instance;
},
saySpecies() {
console.log(this.species);
},
sayName() {
console.log(this.name);
}
};
const player = human.create({
species:'player',
playGame() {
console.log(`I'm playing ${this.game} now !`);
}
})
const lore = player.create({
name:'lore',
game:'MONSTER HUNTER'
})
console.log(lore.playGame());
function Animal() {
this.colors = ['black', 'white']
}
Animal.prototype.getColor = function() {
return this.colors
}
function Dog() {}
Dog.prototype = new Animal()
let dog1 = new Dog()
dog1.colors.push('brown')
let dog2 = new Dog()
console.log(dog2.colors) // ['black', 'white', 'brown']
原型链继承存在的问题:
function Animal(name) {
this.name = name;
this.getName = function () {
return this.name;
}
}
function Dog(name) {
Animal.call(this, name);
}
Dog.prototype = new Animal();
借用构造函数实现继承解决了原型链继承的 2 个问题:引用类型共享问题以及传参问题。但是由于方法必须定义在构造函数中,所以会导致每次创建子类实例都会创建一遍方法。
组合继承结合了原型链和盗用构造函数,将两者的优点集中了起来。基本的思路是使用原型链继承原型上的属性和方法,而通过盗用构造函数继承实例属性。这样既可以把方法定义在原型上以实现重用,又可以让每个实例都有自己的属性。
function Animal(name) {
this.name = name
this.colors = ['black', 'white']
}
Animal.prototype.getName = function() {
return this.name
}
function Dog(name, age) {
Animal.call(this, name)
this.age = age
}
Dog.prototype = new Animal()
Dog.prototype.constructor = Dog
let dog1 = new Dog('奶昔', 2)
dog1.colors.push('brown')
let dog2 = new Dog('哈赤', 1)
console.log(dog2)
// { name: "哈赤", colors: ["black", "white"], age: 1 }
组合继承已经相对完善了,但还是存在问题,它的问题就是调用了 2 次父类构造函数,第一次是在 new Animal(),第二次是在 Animal.call() 这里。
所以解决方案就是不直接调用父类构造函数给子类原型赋值,而是通过创建空函数 F 获取父类原型的副本。
寄生式组合继承写法上和组合继承基本类似,区别是如下这里:
- Dog.prototype = new Animal()
- Dog.prototype.constructor = Dog
+ function F() {}
+ F.prototype = Animal.prototype
+ let f = new F()
+ f.constructor = Dog
+ Dog.prototype = f
//稍微封装下上面添加的代码后:
function object(o) {
function F() {}
F.prototype = o
return new F()
}
function inheritPrototype(child, parent) {
let prototype = object(parent.prototype)
prototype.constructor = child
child.prototype = prototype
}
inheritPrototype(Dog, Animal)
//如果你嫌弃上面的代码太多了,还可以基于组合继承的代码改成最简单的寄生式组合继承:
- Dog.prototype = new Animal()
- Dog.prototype.constructor = Dog
+ Dog.prototype = Object.create(Animal.prototype)
+ Dog.prototype.constructor = Dog
// 为什么要创造一个空函数 不能直接:
+ Dog.prototype = Animal.prototype // x
+ Dog.prototype.constructor = Dog
// 因为 x 行代码让 左右两侧指向同一个引用, 而下一行使 Animal.prototype.constructor 被改写
// includes
const unique = arr => {
if (!Array.isArray(arr)) {
return new Error("type error");
}
const res = [];
for (let elem of arr) {
if (!res.includes(elem)) {
res.push(elem);
}
}
return res;
}
// indexOf
const unique = arr => arr.filter((e, i) => arr.indexOf(e) === i);
// set
const unique = arr => [...new Set(arr)];
数组扁平化就是将 [1, [2, [3]]] 这种多层的数组拍平成一层 [1, 2, 3]。使用 Array.prototype.flat 可以直接将多层数组拍平成一层:
[1, [2, [3]]].flat(2) // [1, 2, 3]
现在就是要实现 flat 这种效果。
ES5 实现:递归。
function flatten(arr) {
var result = [];
for (var i = 0, len = arr.length; i < len; i++) {
if (Array.isArray(arr[i])) {
result = result.concat(flatten(arr[i]))
} else {
result.push(arr[i])
}
}
return result;
}
ES6 实现:
function flatten(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
浅拷贝:只考虑对象类型。
function shallowCopy(obj) {
if (typeof obj !== 'object') return
let newObj = obj instanceof Array ? [] : {}
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = obj[key]
}
}
return newObj
}
简单版深拷贝:只考虑普通对象属性,不考虑内置对象和函数。
function deepClone(obj) {
if (typeof obj !== 'object') return;
var newObj = obj instanceof Array ? [] : {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = typeof obj[key] === 'object' ? deepClone(obj[key]) : obj[key];
}
}
return newObj;
}
// my type
const deepClone = obj => {
if (typeof obj !== 'object' || obj === null) return obj;
const newObj = obj instanceof Array ? [] : {};
for (const [key, value] of Object.entries(obj)) {
newObj[key] = typeof value === 'object' ? deepClone(value) : value;
}
return newObj;
}
复杂版深克隆:基于简单版的基础上,还考虑了内置对象比如 Date、RegExp 等对象和函数以及解决了循环引用的问题。
const isObject = (target) => (typeof target === "object" || typeof target === "function") && target !== null;
function deepClone(target, map = new WeakMap()) {
if (map.get(target)) {
return target;
}
// 获取当前值的构造函数:获取它的类型
let constructor = target.constructor;
// 检测当前对象target是否与正则、日期格式对象匹配
if (/^(RegExp|Date)$/i.test(constructor.name)) {
// 创建一个新的特殊对象(正则类/日期类)的实例
return new constructor(target);
}
if (isObject(target)) {
map.set(target, true); // 为循环引用的对象做标记
const cloneTarget = Array.isArray(target) ? [] : {};
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = deepClone(target[prop], map);
}
}
return cloneTarget;
} else {
return target;
}
}
class EventEmitter {
constructor() {
this.cache = {}
}
on(name, fn) {
if (this.cache[name]) {
this.cache[name].push(fn)
} else {
this.cache[name] = [fn]
}
}
off(name, fn) {
let tasks = this.cache[name]
if (tasks) {
const index = tasks.findIndex(f => f === fn || f.callback === fn)
if (index >= 0) {
tasks.splice(index, 1)
}
}
}
emit(name, once = false, ...args) {
if (this.cache[name]) {
// 创建副本,如果回调函数内继续注册相同事件,会造成死循环
let tasks = this.cache[name].slice()
for (let fn of tasks) {
fn(...args)
}
if (once) {
delete this.cache[name]
}
}
}
}
// 测试
let eventBus = new EventEmitter()
let fn1 = function(name, age) {
console.log(`${name} ${age}`)
}
let fn2 = function(name, age) {
console.log(`hello, ${name} ${age}`)
}
eventBus.on('aaa', fn1)
eventBus.on('aaa', fn2)
eventBus.emit('aaa', false, '布兰', 12)
// '布兰 12'
// 'hello, 布兰 12'
function parseParam(url) {
const paramsStr = /.+\?(.+)$/.exec(url)[1]; // 将 ? 后面的字符串取出来
const paramsArr = paramsStr.split('&'); // 将字符串以 & 分割后存到数组中
let paramsObj = {};
// 将 params 存到对象中
paramsArr.forEach(param => {
if (/=/.test(param)) { // 处理有 value 的参数
let [key, val] = param.split('='); // 分割 key 和 value
val = decodeURIComponent(val); // 解码
val = /^\d+$/.test(val) ? parseFloat(val) : val; // 判断是否转为数字
if (paramsObj.hasOwnProperty(key)) { // 如果对象有 key,则添加一个值
paramsObj[key] = [].concat(paramsObj[key], val);
} else { // 如果对象没有这个 key,创建 key 并设置值
paramsObj[key] = val;
}
} else { // 处理没有 value 的参数
paramsObj[param] = true;
}
})
return paramsObj;
}
function render(template, data) {
const reg = /\{\{(\w+)\}\}/; // 模板字符串正则
if (reg.test(template)) { // 判断模板里是否有模板字符串
const name = reg.exec(template)[1]; // 查找当前模板里第一个模板字符串的字段
template = template.replace(reg, data[name]); // 将第一个模板字符串渲染
return render(template, data); // 递归的渲染并返回渲染后的结构
}
return template; // 如果模板没有模板字符串直接返回
}
测试:
let template = '我是{{name}},年龄{{age}},性别{{sex}}';
let person = {
name: '布兰',
age: 12
}
render(template, person); // 我是布兰,年龄12,性别undefined
与普通的图片懒加载不同,如下这个多做了 2 个精心处理:
let imgList = [...document.querySelectorAll('img')]
let length = imgList.length
const imgLazyLoad = function() {
let count = 0
return (function() {
let deleteIndexList = []
imgList.forEach((img, index) => {
let rect = img.getBoundingClientRect()
if (rect.top < window.innerHeight) {
img.src = img.dataset.src
deleteIndexList.push(index)
count++
if (count === length) {
document.removeEventListener('scroll', imgLazyLoad)
}
}
})
imgList = imgList.filter((img, index) => !deleteIndexList.includes(index))
})()
}
// 这里最好加上防抖处理
document.addEventListener('scroll', imgLazyLoad)
参考:图片懒加载[1]
触发高频事件 N 秒后只会执行一次,如果 N 秒内事件再次触发,则会重新计时。
简单版:函数内部支持使用 this 和 event 对象;
function debounce(func, wait) {
var timeout;
return function () {
var context = this;
var args = arguments;
clearTimeout(timeout)
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
}
使用:
var node = document.getElementById('layout')
function getUserAction(e) {
console.log(this, e) // 分别打印:node 这个节点 和 MouseEvent
node.innerHTML = count++;
};
node.onmousemove = debounce(getUserAction, 1000)
最终版:除了支持 this 和 event 外,还支持以下功能:
function debounce(func, wait, immediate) {
var timeout, result;
var debounced = function () {
var context = this;
var args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
timeout = setTimeout(function(){
timeout = null;
}, wait)
if (callNow) result = func.apply(context, args)
} else {
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
return result;
};
debounced.cancel = function() {
clearTimeout(timeout);
timeout = null;
};
return debounced;
}
使用:
var setUseAction = debounce(getUserAction, 10000, true);
// 使用防抖
node.onmousemove = setUseAction
// 取消防抖
setUseAction.cancel()
参考:JavaScript专题之跟着underscore学防抖
触发高频事件,且 N 秒内只执行一次。
简单版:使用时间戳来实现,立即执行一次,然后每 N 秒执行一次。
function throttle(func, wait) {
var context, args;
var previous = 0;
return function() {
var now = +new Date();
context = this;
args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}
最终版:支持取消节流;另外通过传入第三个参数,options.leading 来表示是否可以立即执行一次,opitons.trailing 表示结束调用的时候是否还要执行一次,默认都是 true。注意设置的时候不能同时将 leading 或 trailing 设置为 false。
function throttle(func, wait, options) {
var timeout, context, args, result;
var previous = 0;
if (!options) options = {};
var later = function() {
previous = options.leading === false ? 0 : new Date().getTime();
timeout = null;
func.apply(context, args);
if (!timeout) context = args = null;
};
var throttled = function() {
var now = new Date().getTime();
if (!previous && options.leading === false) previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
timeout = setTimeout(later, remaining);
}
};
throttled.cancel = function() {
clearTimeout(timeout);
previous = 0;
timeout = null;
}
return throttled;
}
节流的使用就不拿代码举例了,参考防抖的写就行。
参考:JavaScript专题之跟着 underscore 学节流
什么叫函数柯里化?其实就是将使用多个参数的函数转换成一系列使用一个参数的函数的技术。还不懂?来举个例子。
function add(a, b, c) {
return a + b + c
}
add(1, 2, 3)
let addCurry = curry(add)
addCurry(1)(2)(3)
现在就是要实现 curry 这个函数,使函数从一次调用传入多个参数变成多次调用每次传一个参数。
function curry(fn) {
let judge = (...args) => {
if (args.length == fn.length) return fn(...args)
return (...arg) => judge(...args, ...arg)
}
return judge
}
什么是偏函数?偏函数就是将一个 n 参的函数转换成固定 x 参的函数,剩余参数(n - x)将在下次调用全部传入。举个例子:
function add(a, b, c) {
return a + b + c
}
let partialAdd = partial(add, 1)
partialAdd(2, 3)
发现没有,其实偏函数和函数柯里化有点像,所以根据函数柯里化的实现,能够能很快写出偏函数的实现:
function partial(fn, ...args) {
return (...arg) => {
return fn(...args, ...arg)
}
}
如上这个功能比较简单,现在我们希望偏函数能和柯里化一样能实现占位功能,比如:
function clg(a, b, c) {
console.log(a, b, c)
}
let partialClg = partial(clg, '_', 2)
partialClg(1, 3) // 依次打印:1, 2, 3
_ 占的位其实就是 1 的位置。相当于:partial(clg, 1, 2),然后 partialClg(3)。明白了原理,我们就来写实现:
function partial(fn, ...args) {
return (...arg) => {
args[index] =
return fn(...args, ...arg)
}
}
JSONP 核心原理:script 标签不受同源策略约束,所以可以用来进行跨域请求,优点是兼容性好,但是只能用于 GET 请求;
const jsonp = ({ url, params, callbackName }) => {
const generateUrl = () => {
let dataSrc = ''
for (let key in params) {
if (params.hasOwnProperty(key)) {
dataSrc += `${key}=${params[key]}&`
}
}
dataSrc += `callback=${callbackName}`
return `${url}?${dataSrc}`
}
return new Promise((resolve, reject) => {
const scriptEle = document.createElement('script')
scriptEle.src = generateUrl()
document.body.appendChild(scriptEle)
window[callbackName] = data => {
resolve(data)
document.removeChild(scriptEle)
}
})
}
const getJSON = function(url) {
return new Promise((resolve, reject) => {
const xhr = XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject('Mscrosoft.XMLHttp');
xhr.open('GET', url, false);
xhr.setRequestHeader('Accept', 'application/json');
xhr.onreadystatechange = function() {
if (xhr.readyState !== 4) return;
if (xhr.status === 200 || xhr.status === 304) {
resolve(xhr.responseText);
} else {
reject(new Error(xhr.responseText));
}
}
xhr.send();
})
}
Array.prototype.forEach2 = function(callback, thisArg) {
if (this == null) {
throw new TypeError('this is null or not defined')
}
if (typeof callback !== "function") {
throw new TypeError(callback + ' is not a function')
}
const O = Object(this) // this 就是当前的数组
const len = O.length >>> 0 // 后面有解释
let k = 0
while (k < len) {
if (k in O) {
callback.call(thisArg, O[k], k, O);
}
k++;
}
}
参考:forEach#polyfill[2]
O.length >>> 0 是什么操作?就是无符号右移 0 位,那有什么意义嘛?就是为了保证转换后的值为正整数。其实底层做了 2 层转换,第一是非 number 转成 number 类型,第二是将 number 转成 Uint32 类型。感兴趣可以阅读 something >>> 0是什么意思?[3]。
基于 forEach 的实现能够很容易写出 map 的实现:
- Array.prototype.forEach2 = function(callback, thisArg) {
+ Array.prototype.map2 = function(callback, thisArg) {
if (this == null) {
throw new TypeError('this is null or not defined')
}
if (typeof callback !== "function") {
throw new TypeError(callback + ' is not a function')
}
const O = Object(this)
const len = O.length >>> 0
- let k = 0
+ let k = 0, res = []
while (k < len) {
if (k in O) {
- callback.call(thisArg, O[k], k, O);
+ res[k] = callback.call(thisArg, O[k], k, O);
}
k++;
}
+ return res
}
同样,基于 forEach 的实现能够很容易写出 filter 的实现:
- Array.prototype.forEach2 = function(callback, thisArg) {
+ Array.prototype.filter2 = function(callback, thisArg) {
if (this == null) {
throw new TypeError('this is null or not defined')
}
if (typeof callback !== "function") {
throw new TypeError(callback + ' is not a function')
}
const O = Object(this)
const len = O.length >>> 0
- let k = 0
+ let k = 0, res = []
while (k < len) {
if (k in O) {
- callback.call(thisArg, O[k], k, O);
+ if (callback.call(thisArg, O[k], k, O)) {
+ res.push(O[k])
+ }
}
k++;
}
+ return res
}
同样,基于 forEach 的实现能够很容易写出 some 的实现:
- Array.prototype.forEach2 = function(callback, thisArg) {
+ Array.prototype.some2 = function(callback, thisArg) {
if (this == null) {
throw new TypeError('this is null or not defined')
}
if (typeof callback !== "function") {
throw new TypeError(callback + ' is not a function')
}
const O = Object(this)
const len = O.length >>> 0
let k = 0
while (k < len) {
if (k in O) {
- callback.call(thisArg, O[k], k, O);
+ if (callback.call(thisArg, O[k], k, O)) {
+ return true
+ }
}
k++;
}
+ return false
}
Array.prototype.reduce2 = function(callback, initialValue) {
if (this == null) {
throw new TypeError('this is null or not defined')
}
if (typeof callback !== "function") {
throw new TypeError(callback + ' is not a function')
}
const O = Object(this)
const len = O.length >>> 0
let k = 0, acc
if (arguments.length > 1) {
acc = initialValue
} else {
// 没传入初始值的时候,取数组中第一个非 empty 的值为初始值
while (k < len && !(k in O)) {
k++
}
if (k > len) {
throw new TypeError( 'Reduce of empty array with no initial value' );
}
acc = O[k++]
}
while (k < len) {
if (k in O) {
acc = callback(acc, O[k], k, O)
}
k++
}
return acc
}
使用一个指定的 this 值和一个或多个参数来调用一个函数。
实现要点:
Function.prototype.call2 = function (context) {
var context = context || window;
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context.fn(' + args +')');
delete context.fn
return result;
}
apply 和 call 一样,唯一的区别就是 call 是传入不固定个数的参数,而 apply 是传入一个数组。
实现要点:
Function.prototype.apply2 = function (context, arr) {
var context = context || window;
context.fn = this;
var result;
if (!arr) {
result = context.fn();
} else {
var args = [];
for (var i = 0, len = arr.length; i < len; i++) {
args.push('arr[' + i + ']');
}
result = eval('context.fn(' + args + ')')
}
delete context.fn
return result;
}
bind 方法会创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指定为 bind() 的第一个参数,而其余参数将作为新函数的参数,供调用时使用。
实现要点:
Function.prototype.bind2 = function (context) {
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fNOP = function () {};
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(this instanceof fNOP ? this : context, args.concat(bindArgs));
}
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}
new 运算符用来创建用户自定义的对象类型的实例或者具有构造函数的内置对象的实例。
实现要点:
function objectFactory() {
var obj = new Object()
Constructor = [].shift.call(arguments);
obj.__proto__ = Constructor.prototype;
var ret = Constructor.apply(obj, arguments);
// ret || obj 这里这么写考虑了构造函数显示返回 null 的情况
return typeof ret === 'object' ? ret || obj : obj;
};
使用:
function person(name, age) {
this.name = name
this.age = age
}
let p = objectFactory(person, '布兰', 12)
console.log(p) // { name: '布兰', age: 12 }
instanceof 就是判断构造函数的 prototype 属性是否出现在实例的原型链上。
function instanceOf(left, right) {
let proto = left.__proto__
while (true) {
if (proto === null) return false
if (proto === right.prototype) {
return true
}
proto = proto.__proto__
}
}
上面的 left.proto 这种写法可以换成 Object.getPrototypeOf(left)。
Object.create()方法创建一个新对象,使用现有的对象来提供新创建的对象的proto。
Object.create2 = function(proto, propertyObject = undefined) {
if (typeof proto !== 'object' && typeof proto !== 'function') {
throw new TypeError('Object prototype may only be an Object or null.')
if (propertyObject == null) {
new TypeError('Cannot convert undefined or null to object')
}
function F() {}
F.prototype = proto
const obj = new F()
if (propertyObject != undefined) {
Object.defineProperties(obj, propertyObject)
}
if (proto === null) {
// 创建一个没有原型对象的对象,Object.create(null)
obj.__proto__ = null
}
return obj
}
Object.assign2 = function(target, ...source) {
if (target == null) {
throw new TypeError('Cannot convert undefined or null to object')
}
let ret = Object(target)
source.forEach(function(obj) {
if (obj != null) {
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
ret[key] = obj[key]
}
}
}
})
return ret
}
JSON.stringify([, replacer [, space]) 方法是将一个 JavaScript 值(对象或者数组)转换为一个 JSON 字符串。此处模拟实现,不考虑可选的第二个参数 replacer 和第三个参数 space,如果对这两个参数的作用还不了解,建议阅读 MDN[4] 文档。
基本数据类型:
函数类型:转换之后是 undefined
如果是对象类型(非函数)
对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。
function jsonStringify(data) {
let dataType = typeof data;
if (dataType !== 'object') {
let result = data;
//data 可能是 string/number/null/undefined/boolean
if (Number.isNaN(data) || data === Infinity) {
//NaN 和 Infinity 序列化返回 "null"
result = "null";
} else if (dataType === 'function' || dataType === 'undefined' || dataType === 'symbol') {
//function 、undefined 、symbol 序列化返回 undefined
return undefined;
} else if (dataType === 'string') {
result = '"' + data + '"';
}
//boolean 返回 String()
return String(result);
} else if (dataType === 'object') {
if (data === null) {
return "null"
} else if (data.toJSON && typeof data.toJSON === 'function') {
return jsonStringify(data.toJSON());
} else if (data instanceof Array) {
let result = [];
//如果是数组
//toJSON 方法可以存在于原型链中
data.forEach((item, index) => {
if (typeof item === 'undefined' || typeof item === 'function' || typeof item === 'symbol') {
result[index] = "null";
} else {
result[index] = jsonStringify(item);
}
});
result = "[" + result + "]";
return result.replace(/'/g, '"');
} else {
//普通对象
/**
* 循环引用抛错(暂未检测,循环引用时,堆栈溢出)
* symbol key 忽略
* undefined、函数、symbol 为属性值,被忽略
*/
let result = [];
Object.keys(data).forEach((item, index) => {
if (typeof item !== 'symbol') {
//key 如果是symbol对象,忽略
if (data[item] !== undefined && typeof data[item] !== 'function'
&& typeof data[item] !== 'symbol') {
//键值如果是 undefined、函数、symbol 为属性值,忽略
result.push('"' + item + '"' + ":" + jsonStringify(data[item]));
}
}
});
return ("{" + result + "}").replace(/'/g, '"');
}
}
}
参考:实现 JSON.stringify[5]
介绍 2 种方法实现:
第一种方式最简单,也最直观,就是直接调用 eval,代码如下:
var json = '{"a":"1", "b":2}';
var obj = eval("(" + json + ")"); // obj 就是 json 反序列化之后得到的对象
但是直接调用 eval 会存在安全问题,如果数据中可能不是 json 数据,而是可执行的 JavaScript 代码,那很可能会造成 XSS 攻击。因此,在调用 eval 之前,需要对数据进行校验。
var rx_one = /^[\],:{}\s]*$/;
var rx_two = /\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4})/g;
var rx_three = /"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(?:[eE][+\-]?\d+)?/g;
var rx_four = /(?:^|:|,)(?:\s*\[)+/g;
if (
rx_one.test(
json.replace(rx_two, "@")
.replace(rx_three, "]")
.replace(rx_four, "")
)
) {
var obj = eval("(" +json + ")");
}
参考:JSON.parse 三种实现方式[6]
Function 与 eval 有相同的字符串参数特性。
var json = '{"name":"小姐姐", "age":20}';
var obj = (new Function('return ' + json))();
实现 Promise 需要完全读懂 Promise A+ 规范[7],不过从总体的实现上看,有如下几个点需要考虑到:
const PENDING = 'pending';
const FULFILLED = 'fulfilled';
const REJECTED = 'rejected';
class Promise {
constructor(executor) {
this.status = PENDING;
this.value = undefined;
this.reason = undefined;
this.onResolvedCallbacks = [];
this.onRejectedCallbacks = [];
let resolve = (value) = > {
if (this.status === PENDING) {
this.status = FULFILLED;
this.value = value;
this.onResolvedCallbacks.forEach((fn) = > fn());
}
};
let reject = (reason) = > {
if (this.status === PENDING) {
this.status = REJECTED;
this.reason = reason;
this.onRejectedCallbacks.forEach((fn) = > fn());
}
};
try {
executor(resolve, reject);
} catch (error) {
reject(error);
}
}
then(onFulfilled, onRejected) {
// 解决 onFufilled,onRejected 没有传值的问题
onFulfilled = typeof onFulfilled === "function" ? onFulfilled : (v) = > v;
// 因为错误的值要让后面访问到,所以这里也要抛出错误,不然会在之后 then 的 resolve 中捕获
onRejected = typeof onRejected === "function" ? onRejected : (err) = > {
throw err;
};
// 每次调用 then 都返回一个新的 promise
let promise2 = new Promise((resolve, reject) = > {
if (this.status === FULFILLED) {
//Promise/A+ 2.2.4 --- setTimeout
setTimeout(() = > {
try {
let x = onFulfilled(this.value);
// x可能是一个proimise
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
}
if (this.status === REJECTED) {
//Promise/A+ 2.2.3
setTimeout(() = > {
try {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
}
if (this.status === PENDING) {
this.onResolvedCallbacks.push(() = > {
setTimeout(() = > {
try {
let x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
});
this.onRejectedCallbacks.push(() = > {
setTimeout(() = > {
try {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
});
}
});
return promise2;
}
}
const resolvePromise = (promise2, x, resolve, reject) = > {
// 自己等待自己完成是错误的实现,用一个类型错误,结束掉 promise Promise/A+ 2.3.1
if (promise2 === x) {
return reject(
new TypeError("Chaining cycle detected for promise #<Promise>"));
}
// Promise/A+ 2.3.3.3.3 只能调用一次
let called;
// 后续的条件要严格判断 保证代码能和别的库一起使用
if ((typeof x === "object" && x != null) || typeof x === "function") {
try {
// 为了判断 resolve 过的就不用再 reject 了(比如 reject 和 resolve 同时调用的时候) Promise/A+ 2.3.3.1
let then = x.then;
if (typeof then === "function") {
// 不要写成 x.then,直接 then.call 就可以了 因为 x.then 会再次取值,Object.defineProperty Promise/A+ 2.3.3.3
then.call(
x, (y) = > {
// 根据 promise 的状态决定是成功还是失败
if (called) return;
called = true;
// 递归解析的过程(因为可能 promise 中还有 promise) Promise/A+ 2.3.3.3.1
resolvePromise(promise2, y, resolve, reject);
}, (r) = > {
// 只要失败就失败 Promise/A+ 2.3.3.3.2
if (called) return;
called = true;
reject(r);
});
} else {
// 如果 x.then 是个普通值就直接返回 resolve 作为结果 Promise/A+ 2.3.3.4
resolve(x);
}
} catch (e) {
// Promise/A+ 2.3.3.2
if (called) return;
called = true;
reject(e);
}
} else {
// 如果 x 是个普通值就直接返回 resolve 作为结果 Promise/A+ 2.3.4
resolve(x);
}
};
Promise 写完之后可以通过 promises-aplus-tests 这个包对我们写的代码进行测试,看是否符合 A+ 规范。不过测试前还得加一段代码:
// promise.js
// 这里是上面写的 Promise 全部代码
Promise.defer = Promise.deferred = function () {
let dfd = {}
dfd.promise = new Promise((resolve,reject)=>{
dfd.resolve = resolve;
dfd.reject = reject;
});
return dfd;
}
module.exports = Promise;
全局安装:
npm i promises-aplus-tests -g
终端下执行验证命令:
promises-aplus-tests promise.js
上面写的代码可以顺利通过全部 872 个测试用例。
参考:
Promsie.resolve(value) 可以将任何值转成值为 value 状态是 fulfilled 的 Promise,但如果传入的值本身是 Promise 则会原样返回它。
Promise.resolve = function(value) {
// 如果是 Promsie,则直接输出它
if(value instanceof Promise){
return value
}
return new Promise(resolve => resolve(value))
}
参考:深入理解 Promise[10]
和 Promise.resolve() 类似,Promise.reject() 会实例化一个 rejected 状态的 Promise。但与 Promise.resolve() 不同的是,如果给 Promise.reject() 传递一个 Promise 对象,则这个对象会成为新 Promise 的值。
Promise.reject = function(reason) {
return new Promise((resolve, reject) => reject(reason))
}
Promise.all 的规则是这样的:
Promise.all = function(promiseArr) {
let index = 0, result = []
return new Promise((resolve, reject) => {
promiseArr.forEach((p, i) => {
Promise.resolve(p).then(val => {
index++
result[i] = val
if (index === promiseArr.length) {
resolve(result)
}
}, err => {
reject(err)
})
})
})
}
Promise.race 会返回一个由所有可迭代实例中第一个 fulfilled 或 rejected 的实例包装后的新实例。
Promise.race = function(promiseArr) {
return new Promise((resolve, reject) => {
promiseArr.forEach(p => {
Promise.resolve(p).then(val => {
resolve(val)
}, err => {
rejecte(err)
})
})
})
}
Promise.allSettled 的规则是这样:
Promise.allSettled = function(promiseArr) {
let result = []
return new Promise((resolve, reject) => {
promiseArr.forEach((p, i) => {
Promise.resolve(p).then(val => {
result.push({
status: 'fulfilled',
value: val
})
if (result.length === promiseArr.length) {
resolve(result)
}
}, err => {
result.push({
status: 'rejected',
reason: err
})
if (result.length === promiseArr.length) {
resolve(result)
}
})
})
})
}
Promise.any 的规则是这样:
Promise.any = function(promiseArr) {
let index = 0
return new Promise((resolve, reject) => {
if (promiseArr.length === 0) return
promiseArr.forEach((p, i) => {
Promise.resolve(p).then(val => {
resolve(val)
}, err => {
index++
if (index === promiseArr.length) {
reject(new AggregateError('All promises were rejected'))
}
})
})
})
}
this 为undefinedstate调用render() class Weather extends React.Component {
state = {isHot: true}
render() {
const {isHot} = this.state;
return <h1 id="h1" onClick={this.handleClick}>today is a {isHot ? 'sunday' : 'rainy'} day!!</h1>;
}
handleClick = () => this.setState({isHot: !(this.state.isHot)});
}
ReactDOM.render(<Weather/>, document.getElementById("test"));
props需要使用static// 须引入 props 库
class Demo extends React.Component {
static propTypes = {
name: PropTypes.string.isRequired,
age: PropTypes.number,
sex: PropTypes.string,
}
render() {
const {name, age, sex} = this.props;
return (
<div>
<ul>
<li>{name}</li>
<li>{age}</li>
<li>{sex}</li>
</ul>
</div>
)
}
}
const person = {
name: 'lore',
age: 26,
sex: 'male',
}
ReactDOM.render(<Demo {...person}/>, document.getElementById("test"));
class Demo extends React.Component {
render() {
return (
<div>
<input type="text" ref="input"/>
<button onClick={this.show}>click me!</button>
</div>
)
}
show = () => console.log(this.refs.input.value);
}
class Demo extends React.Component {
render() {
return (
<div>
<input type="text" ref={c => this.input = c}/>
<button onClick={this.show}>click me!</button>
</div>
)
}
show = () => console.log(this.input.value);
}
class Demo extends React.Component {
container = React.createRef();
render() {
return (
<div>
<input type="text" ref={this.container}></input>
<button onClick={this.show}>click me!</button>
</div>
)
}
show = () => this.container.current.value;
}
state控制的组件 class Demo extends React.Component {
state = {
username: '',
password: '',
}
render() {
return (
<form onSubmit={this.handleLogin}>
<input type="text" onChange={this.saveFormData('username')} />
<input type="password" onChange={this.saveFormData('password')} />
<button>Login in</button>
</form>
)
}
// 柯里化 f(type)(event)
saveFormData = (type) => {
return event => this.setState({[type]: event.target.value});
}
handleLogin = (event) => {
event.preventDefault();
console.log(this.input.value);
}
}
componentWillUpdate()getSnapshotBeforeUpdate()Fiber 架构铺路
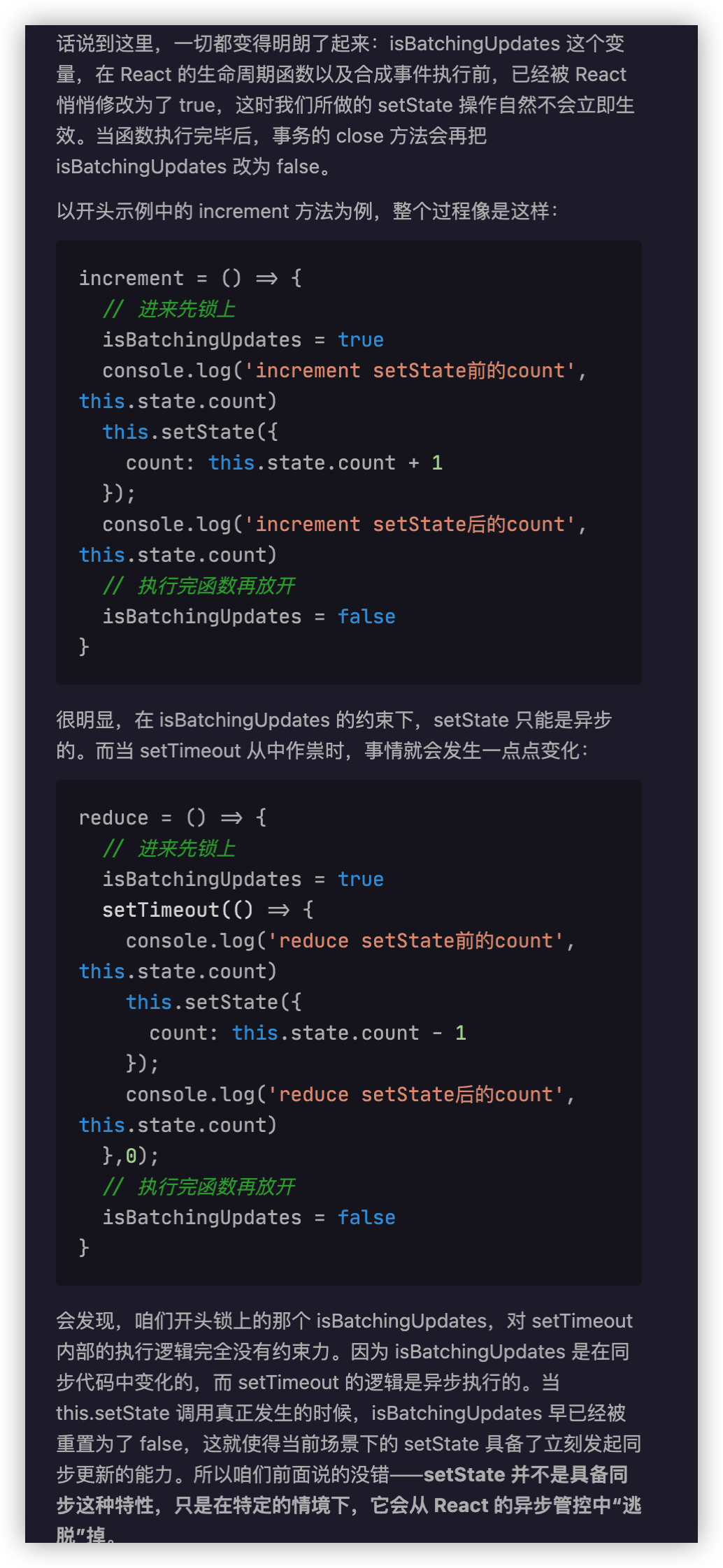
同步渲染的递归调用栈是非常深的,只有最底层的调用返回了,整个渲染过程才会开始逐层返回。这个漫长且不可打断的更新过程,将会带来用户体验层面的巨大风险:**同步渲染一旦开始,便会牢牢抓住主线程不放,直到递归彻底完成。在这个过程中,浏览器没有办法处理任何渲染之外的事情,会进入一种**无法处理用户交互的状态。因此若渲染时间稍微长一点,页面就会面临卡顿甚至卡死的风险。
而 React 16 引入的 Fiber 架构,恰好能够解决掉这个风险:Fiber 会将一个大的更新任务拆解为许多个小任务。每当执行完一个小任务时,渲染线程都会把主线程交回去,看看有没有优先级更高的工作要处理,确保不会出现其他任务被“饿死”的情况,进而避免同步渲染带来的卡顿。在这个过程中,渲染线程不再“一去不回头”,而是可以被打断的,这就是所谓的“异步渲染”
fiber 架构下,render前的异步请求会导致非常严重的 Bug (异步中的异步 => 不可预测)
// 为什么父路由会覆盖子路由
const App = () => (
<>
<Routes>
<Route path="home" element={<Home />}>
<Route path="shop" element={<Shop />} />
</Route>
</Routes>
</>
)
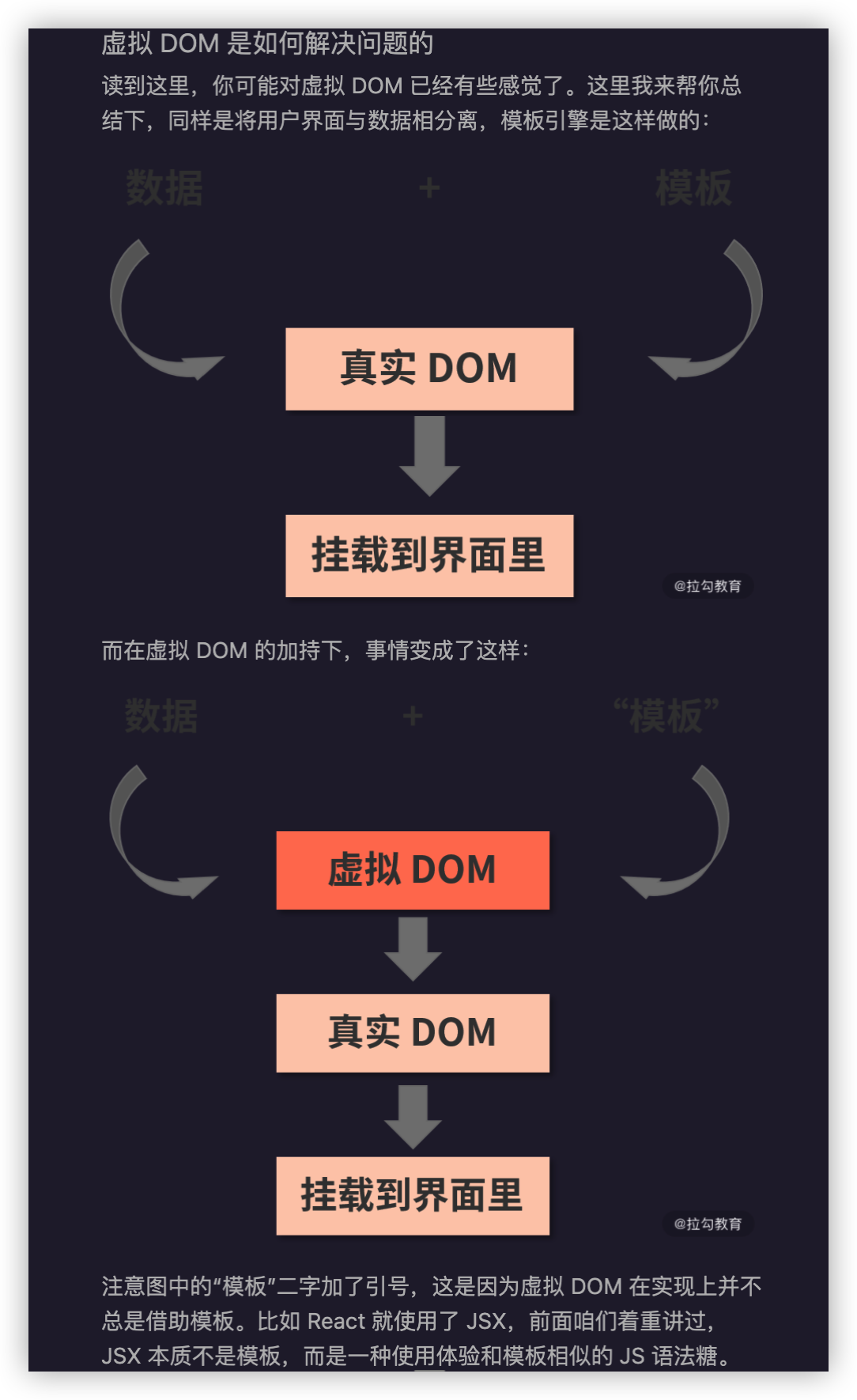
UI = render(data / state) 或 UI = f(data)
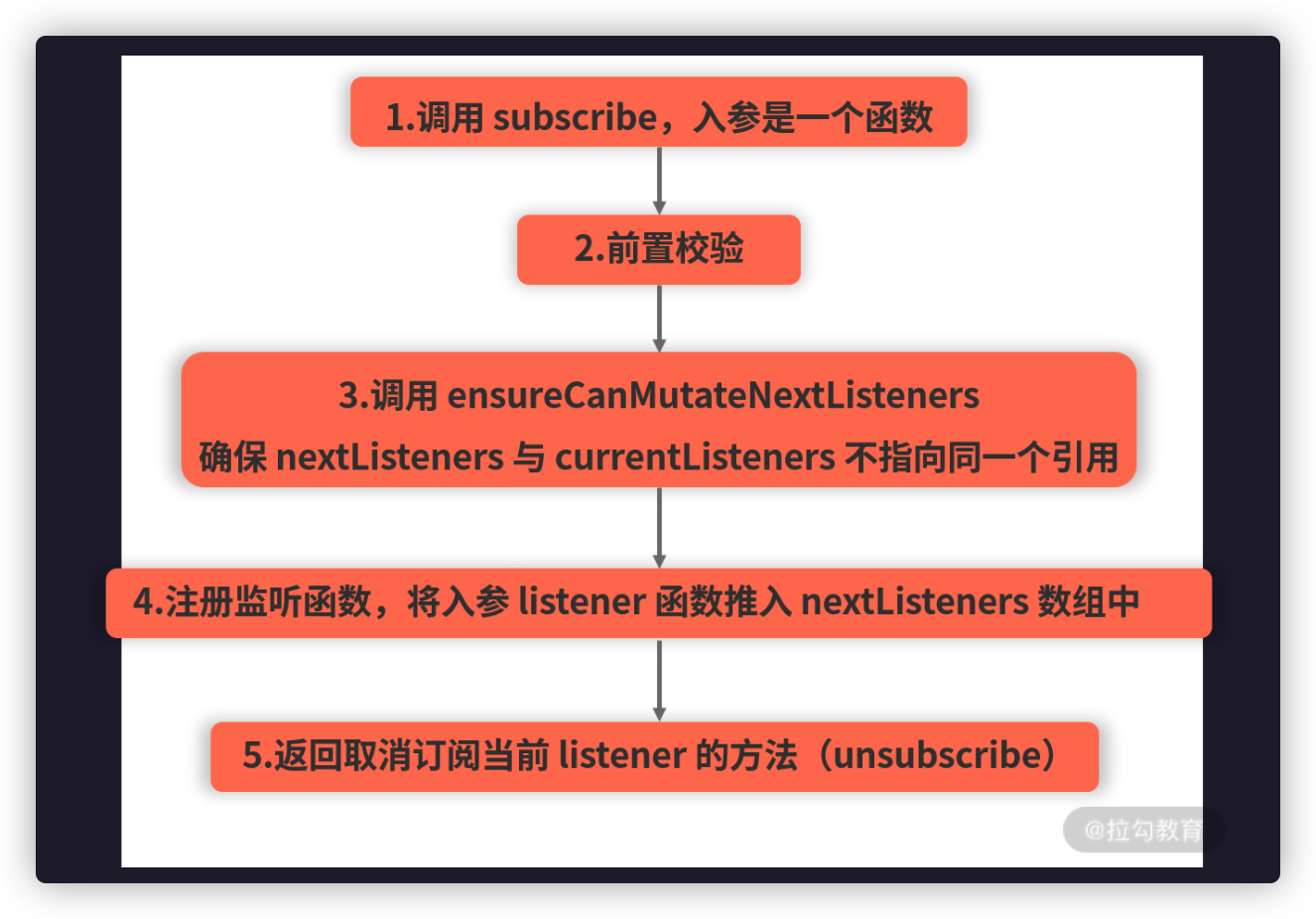
发布-订阅模式中有两个关键的动作:事件的监听(订阅)和事件的触发(发布),这两个动作自然而然地对应着两个基本的 API 方法。
on():负责注册事件的监听器,指定事件触发时的回调函数。
emit():负责触发事件,可以通过传参使其在触发的时候携带数据 。
最后,只进不出总是不太合理的,我们还要考虑一个 off() 方法,必要的时候用它来删除用不到的监听器:
Redux 是 JavaScript 状态容器,它提供可预测的状态管理。
在 Redux 的整个工作过程中,数据流是严格单向的
statestore对象里

“切面”与业务逻辑是分离的,因此 AOP 是一种典型的 “非侵入式”的逻辑扩充思路。
在日常开发中,像“日志追溯”“异步工作流处理”“性能打点”这类和业务逻辑关系不大的功能,我们都可以考虑把它们抽到“切面”中去做。
面向切面编程带来的利好是非常明显的。从 Redux 中间件机制中,不难看出,面向切面思想在很大程度上提升了我们组织逻辑的灵活度与干净度,帮助我们规避掉了逻辑冗余、逻辑耦合这类问题。通过将“切面”与业务逻辑剥离,开发者能够专注于业务逻辑的开发,并通过“即插即用”的方式自由地组织自己想要的扩展功能。
函数组件会捕获 render 内部的状态,这是两类组件最大的不同。
基于 Js 闭包
类组件和函数组件之间,纵有千差万别,但最不能够被我们忽视掉的,是心智模式层面的差异,是面向对象和函数式编程这两套不同的设计思想之间的差异。说得更具体一点,函数组件更加契合 React 框架的设计理念
UI = f(data)
函数组件真正地把数据和渲染绑定到了一起。
UI = f(data)
为什么顺序如此重要?
Hooks 的正常运作,在底层依赖于顺序链表
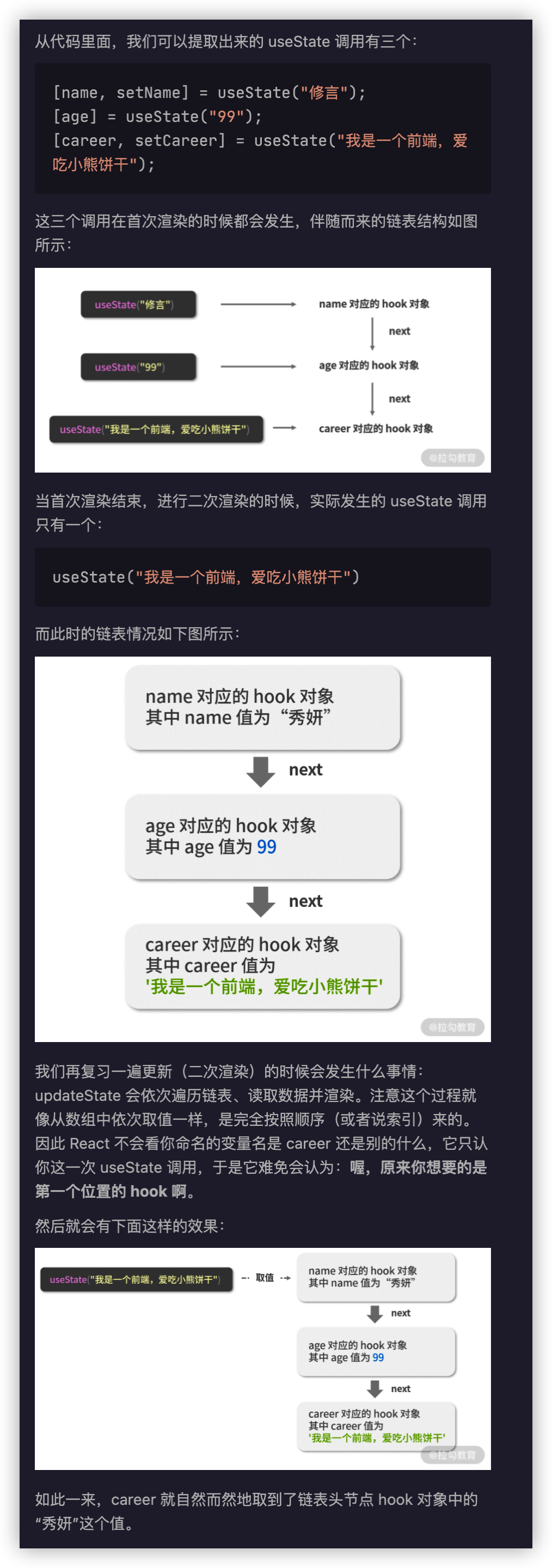

useState reduce 的结果则是相同 --> 闭包函数组件里面的useState只会把某次执行时的state赋值给某个变量,是不变的,你在当前上下文只能获取当前状态切片的state,修改后的是在下一次执行上下文里获取的,所以react文档里说依赖了哪些state,就一定要在[]里写上,不然实际开发中可能会遇到“缓存”bug。
大家在入门前端的时候,想必都听说过这样一个结论:JavaScript 是单线程的,浏览器是多线程的。
对于多线程的浏览器来说,它除了要处理 JavaScript 线程以外,还需要处理包括事件系统、定时器/延时器、网络请求等各种各样的任务线程,这其中,自然也包括负责处理 DOM 的UI 渲染线程。而 JavaScript 线程是可以操作 DOM 的。
这意味着什么呢?试想如果渲染线程和 JavaScript 线程同时在工作,那么渲染结果必然是难以预测的:比如渲染线程刚绘制好的画面,可能转头就会被一段 JavaScript 给改得面目全非。这就决定了JavaScript 线程和渲染线程必须是互斥的:这两个线程不能够穿插执行,必须串行。当其中一个线程执行时,另一个线程只能挂起等待。
具有相似特征的还有事件线程,浏览器的 Event-Loop 机制决定了事件任务是由一个异步队列来维持的。当事件被触发时,对应的任务不会立刻被执行,而是由事件线程把它添加到任务队列的末尾,等待 JavaScript 的同步代码执行完毕后,在空闲的时间里执行出队。
在这样的机制下,若 JavaScript 线程长时间地占用了主线程,那么渲染层面的更新就不得不长时间地等待,界面长时间不更新,带给用户的体验就是所谓的“卡顿”。一般页面卡顿的时候,你会做什么呢?我个人的习惯是更加频繁地在页面上点来点去,期望页面能够给我哪怕一点点的响应。遗憾的是,事件线程也在等待 JavaScript,这就导致你触发的事件也将是难以被响应的。
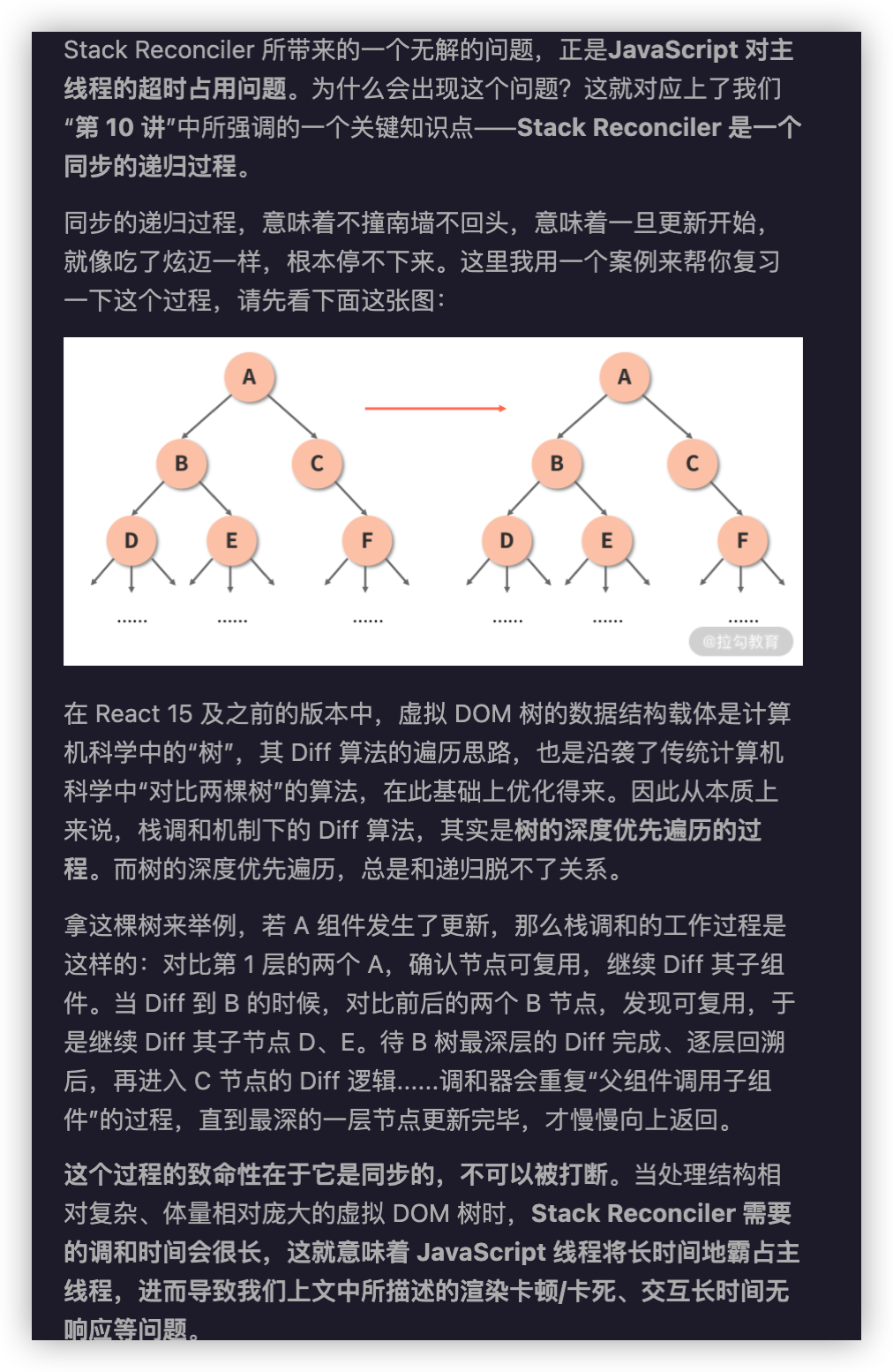
“双缓冲”模式其实是一种在游戏领域由来已久的经典设计模式。为了帮助你快速理解它,这里我先举一个生活中的例子:假如你去看一场总时长只有 1 个小时的话剧,这场话剧中场不休息,需要不间断地演出。
按照剧情的需求,半个小时处需要一次转场。所谓转场,就是说话剧舞台的灯光、布景、氛围等全部要切换到另一种风格里去。在不中断演出的情况下,想要实现转场,怎么办呢?场务工作做得再快,也要十几二十分钟,这对一场时长 1 小时的话剧来说,实在太漫长了。观众也无法接受这样的剧情“卡顿”体验。
有一种解法,那就是准备两个舞台来做这场戏,当第一个舞台处于使用中时,第二个舞台的布局已经完成。这样当第一个舞台的表演结束时,只需要把第一个舞台的灯光灭掉,第二个舞台的灯光亮起,就可以做到剧情的无缝衔接了。
事实上,在真实的话剧中,我们也确实常常看到这样的画面——演员从舞台的左侧走到了右侧,灯光一切换,就从卧室(左侧舞台)走到了公园(右侧舞台);又从公园(右侧舞台)走到了办公室(左侧舞台)。左侧舞台的布景从卧室变成了办公室,这个过程正是在演员利用右侧舞台表演时完成的。
在这个过程中,我们可以认为,左侧舞台和右侧舞台分别是两套缓冲数据,而呈现在观众眼前的连贯画面,就是不同的缓冲数据交替被读取后的结果。
在计算机图形领域,通过让图形硬件交替读取两套缓冲数据,可以实现画面的无缝切换,减少视觉效果上的抖动甚至卡顿。而在 React 中,双缓冲模式的主要利好,则是能够帮我们较大限度地实现 Fiber 节点的复用,从而减少性能方面的开销。
在 React 中,current 树与 workInProgress 树,两棵树可以对标“双缓冲”模式下的两套缓冲数据:当 current 树呈现在用户眼前时,所有的更新都会由 workInProgress 树来承接。workInProgress 树将会在用户看不到的地方(内存里)悄悄地完成所有改变,直到“灯光”打到它身上,也就是 current 指针指向它的时候,此时就意味着 commit 阶段已经执行完毕,workInProgress 树变成了那棵呈现在界面上的 current 树。
原理都是减少 render 的次数
目的都是实现组件逻辑的复用
高阶组件指的就是参数为组件,返回值为新组件的函数。没错,高阶组件本质上是一个函数。下面是一个简单的高阶组件示例:
const withProps = (WrappedComponent) => {
const targetComponent = (props) => (
<div className="wrapper-container">
<WrappedComponent {...props} />
</div>
);
return targetComponent;
};
在这段代码中,withProps 就是一个高阶组件。
现在我们考虑这样一种情况:我有一个名为 checkUserAccess 的方法,这个方法专门用来校验用户的身份是否合法,若不合法,那么一部分组件就要根据这个不合法的身份调整自身的展示逻辑(比如查看个人信息界面需要提示“请校验身份”等)。
假如说页面中的 A、B、C、D、E 五个组件都需要甄别用户身份是否合法,那么这五个组件在理论上都需要先请求一遍 checkUserAccess 这个接口。但一个一个对组件进行修改未免太麻烦了,我们期望对“获取 checkUserAccess 接口信息,并通知到对应组件”这层逻辑进行复用,这时候就可以请出高阶组件来帮忙了。
我们可以像下面代码这样在高阶组件中定义这层通用的逻辑:
// 假设 checkUserAccess 已经在 utils 文件中被封装为了一段独立的逻辑
import checkUserAccess from './utils
// 用高阶组件包裹目标组件
const withCheckAccess = (WrappedComponent) => {
// 这部分是通用的逻辑:判断用户身份是否合法
const isAccessible = checkUserAccess()
// 将 isAccessible(是否合法) 这个信息传递给目标组件
const targetComponent = (props) => (
<div className="wrapper-container">
<WrappedComponent {...props} isAccessible={isAccessible} />
</div>
);
return targetComponent;
};
这样当我们需要为某个组件复用这层请求逻辑的时候,只需要直接用 withCheckAccess 包裹这个组件就可以了。以 A 组件为例,假设 A 组件的原始版本为 AComponent,那么包裹它的形式就是下面代码这样:
const EnhancedAComponent = withCheckAccess(Acomponent);
术语“render prop”是指一种在 React 组件之间使用一个值为函数的 prop 共享代码的简单技术。——React 官方
render props 是 React 中复用组件逻辑的另一种思路,它在实现上和高阶组件有异曲同工之妙——两者都是把通用的逻辑提取到某一处。区别主要在于使用层面,高阶组件的使用姿势是用“函数”包裹“组件”,而 render props 恰恰相反,它强调的是用“组件”包裹“函数”。
一个简单的 render props 可以是这样的,见下面代码:
import React from 'react'
const RenderChildren = (props) => {
return(
<React.Fragment>
{props.children(props)}
</React.Fragment>
);
};
RenderChildren 将渲染它所有的子组件。从这段代码里,你需要把握住两个要点:
第 1 点相对明显一点,你可能会对第 2 点感到迷惑。没关系,我们直接来看 RenderChildren 的使用方式,请看下面代码:
<RenderChildren>
{() => <p>我是 RenderChildren 的子组件</p>}
</RenderChildren>
RenderChildren 本身是一个 React 组件,它可以包裹其他的 React 组件。一般来说,我们习惯于看到的包裹形式是“标签包裹着标签”,也就是下面代码演示的这种效果:
<RenderChildren>
<p>我是 RenderChildren 的子组件</p>
</RenderChildren>
但在 render props 这种模式下,它要求被 render props 组件标签包裹的一定是个函数,也就是所谓的“函数作为子组件传入”。这样一来,render props 组件就可以通过调用这个函数,传递 props,从而实现和目标组件的通信了。
这里我仍然以 checkUserAccess 这个场景举例。使用 render props 复用 checkUserAccess 这段逻辑,我们可以这样做,请看下面代码:
// 假设 checkUserAccess 已经在 utils 文件中被封装为了一段独立的逻辑
import checkUserAccess from './utils
// 定义 render props 组件
const CheckAccess = (props) => {
// 这部分是通用的逻辑:判断用户身份是否合法
const isAccessible = checkUserAccess()
// 将 isAccessible(是否合法) 这个信息传递给目标组件
return <React.Fragment>
{props.children({ ...props, isAccessible })}
</React.Fragment>
};
接下来 CheckAccess 子组件就可以这样获取 isAccessible 的值,见下面代码:
<CheckAccess>
{
(props) => {
const { isAccessible } = props;
return <ChildComponent {...props} isAccessible={isAccessible} />
}
}
</CheckAccess>
到这里,“函数作为子组件传入”这种情况,我们已经了解了它的来龙去脉。但其实,对于 render props 这种模式来说,函数并不一定要作为子组件传入,它也可以以任意属性名传入,只要 render props 组件可以感知到它就行。
举个例子,我可以允许函数通过一个名为 checkTaget 的属性传入 render props 组件,那么 CheckAccess 组件只需要改写一下它接收函数的形式即可,见下面代码:
// 假设 checkUserAccess 已经在 utils 文件中被封装为了一段独立的逻辑
import checkUserAccess from './utils
// 定义 render props 组件
const CheckAccess = (props) => {
// 这部分是通用的逻辑:判断用户身份是否合法
const isAccessible = checkUserAccess()
// 将 isAccessible(是否合法) 这个信息传递给目标组件
return <React.Fragment>
{props.checkTaget({ ...props, isAccessible })}
</React.Fragment>
};
在使用 CheckAccess 组件的时候,我们将函数放在 checkTaget 中传入组件即可,见下面代码:
<CheckAccess
checkTaget={(props) => {
const { isAccessible } = props;
return <ChildComponent {...props} isAccessible={isAccessible} />
}}
/>
像这样使用 render props,也是完全可以的。
读到这里,你不免会产生这样的困惑:高阶组件和 render props 都能复用逻辑,那我到底用哪个好呢?
这里我先给出结论:render props 将是你更好的选择,因为它更灵活。这“更灵活”从何说起呢?
render props 和高阶组件一个非常重要的区别,在于对数据的处理上:在高阶组件中,目标组件对于数据的获取没有主动权,数据的分发逻辑全部收敛在高阶组件的内部;而在 render props 中,除了父组件可以对数据进行分发处理之外,子组件也可以选择性地对数据进行接收。
这样说你可能会觉得有点抽象,我举个例子:假如说我们现在多出一个 F 组件,它同样需要 checkUserAccess 这段逻辑。但是这个 F 组件是一个老组件,它识别不了 props.isAccessible,只认识 props.isValidated。带着这个需求,我们先来看看高阶组件怎么解决问题。原有的高阶组件逻辑是下面这样的:
// 假设 checkUserAccess 已经在 utils 文件中被封装为了一段独立的逻辑
import checkUserAccess from './utils
// 用高阶组件包裹目标组件
const withCheckAccess = (WrappedComponent) => {
// 这部分是通用的逻辑:判断用户身份是否合法
const isAccessible = checkUserAccess()
// 将 isAccessible(是否合法) 这个信息传递给目标组件
const targetComponent = (props) => (
<div className="wrapper-container">
<WrappedComponent {...props} isAccessible={isAccessible} />
</div>
);
return targetComponent;
};
它会不由分说地给所有组件安装上 isAccessible 这个变量。要想让它适配 F 组件的逻辑,最直接的一个思路就是在 withCheckAccess 中增加一个组件类型的判断,一旦判断出当前入参是 F 组件,就专门将 isAccessible 改名为 isValidated。
这样做虽然能够暂时解决问题,但这并不是一个灵活的解法:假如需要改属性名的组件越来越多,那么 withCheckAccess 内部将不可避免变得越来越臃肿,长此以往将难以维护。
事实上,在软件设计模式中,有一个非常重要的原则,叫“开放封闭原则”。一个好的模式,应该尽可能做到对拓展开放,对修改封闭。
当我们发现 withCheckAccess 的内部逻辑需要频繁地跟随需求的变化而变化时,此时就应该提高警惕了,因为这已经违反了“对修改封闭”这一原则。
处理同样的需求,render props 就能够在保全“开放封闭”原则的基础上,帮我们达到目的。
前面说过,在 render props 中,除了父组件可以对数据进行分发处理之外,子组件也可以选择性地对数据进行接收。这就意味着我们可以在新增的 F 组件相关的逻辑中把数据适配这件事情给做掉(如下面代码所示),而不会影响老的 CheckAccess 组件中的逻辑。
<CheckAccess>
{
(props) => {
const { isAccessible } = props;
return <ChildComponent {...props} isValidated={isAccessible} />
}
}
</CheckAccess>
这样一来,不管你新来的组件有多少个,需要变更的属性名有多少个,影响面都会被牢牢地控制在“新增逻辑”这个范畴里。契合了“开放封闭”原则的 render props 模式显然比高阶组件灵活多了。
单一职责原则又叫“单一功能原则”,它指的是一个类或者模块应该有且只有一个改变的原因。通俗来讲,就是说咱们的组件功能要尽可能地聚合,不要试图让一个组件做太多的事情。
无状态组件这个概念我们在第 06 讲中已经介绍过了,这里简单复习一下:
函数组件顾名思义,就是以函数的形态存在的 React 组件。早期并没有 React-Hooks 的加持,函数组件内部无法定义和维护 state,因此它还有一个别名叫“无状态组件”。
如下面代码所示,就是一个典型的无状态组件:
function DemoFunction(props) {
const { text } = props
return (
<div className="demoFunction">
<p>{`function 组件所接收到的来自外界的文本内容是:[${text}]`}</p>
</div>
);
}
无状态组件不一定是函数组件,不维护内部状态的类组件也可以被认为是无状态组件。 相比之下,能够在组件内部维护状态、管理数据的组件,就是“有状态组件”。
有状态组件和无状态组件有很多别名,有的书籍里也会管它们叫“容器组件”和“展示组件”,甚至“聪明组件”和“傻瓜组件”。不管叫啥,核心目的就一个——把数据处理和界面渲染这两个工作剥离开来。
为什么要这样做?别忘了,React 的核心特征是“数据驱动视图”,我们经常用下图的公式来表达它的工作模式:

因此对一个 React 组件来说,它做的事情说到底无外乎是这两件:
我们当然也可以在一个组件里面做完这两件事情,但这样不够优雅。
按照“单一职责”的原则,我们应该将数据处理的逻辑和界面渲染的逻辑剥离到不同的组件中去,这样功能模块的组合将会更加灵活,也会更加有利于逻辑的复用。此外,单一职责还能够帮助我们尽可能地控制变更范围,降低代码的维护成本:当数据相关的逻辑发生变化时,我们只需要去修改有状态组件就可以了,无状态组件将完全不受影响。
设计模式虽好,但它并非万能。
就 React 来说,无论是高阶组件,还是 render props,两者的出现都是为了弥补类组件在“逻辑复用”这个层面的不灵活性。它们各自都有着自己的不足,这些不足包括但不限于以下几点:
总体来看,“HOC/render props+类组件”这种研发模式,还是不够到位。当设计模式解决不了问题时,我们本能地需要从编程模式上寻找答案。于是便有了如今大家在 React 中所看到的 “函数式编程”对“面向对象”的补充(并且大有替代之势),有了今天我们所看到的“一切皆可 Hooks”的大趋势。
现在,当我们想要去复用一段逻辑时,第一反应肯定不是“高阶函数”或者“render props”,而应该是“自定义 Hook”。Hooks 能够很好地规避掉旧时类组件中各种设计模式带来的弊端,比如说它不存在嵌套地狱,允许属性重命名、允许我们在任何需要它的地方引入并访问目标状态等。由此可以看出,一个好的编程模式可以帮我们节约掉大量“打补丁”式地学习各种组件设计模式的时间。框架设计越合理,开发者的工作就越轻松。
本讲,我们围绕“React 组件设计模式”这一专题进行学习。在认识高阶组件、render props 两种经典设计模式的同时,也对“单一职责”“开放封闭”这两个重要的软件设计原则形成了初步的认识。
软件领域没有银弹,就算有,也不可能是设计模式。通过本讲的学习,相信你在认识设计模式的利好之余,也认识到了它的局限性。在此基础上,相信你会对 React-Hooks 及其背后的“函数式编程”思想建立更加强烈的正面认识。
作为团队自研前端框架方向的负责人,我在实际工作中需要调研和深扒的框架类型可能会比大家想象的多得多。那么面对一个陌生的前端框架,我们应该怎样做才能够高效且平稳地完成从“小工”到“专家”的蜕变呢?
这个问题其实是没有标准答案的,它和每个人的学习习惯、学习效率甚至元认知能力都有关系。但我想总有一些具体到行为上的规律是可以复用的。今天我想和你分享的,就是一部分我在团队的新人包括实习生同学身上验证过的、可执行度较高的学习经验,希望能够对你日后的生涯道路有所帮助。
在实际的读者调研中,我发现很多同学对 React 官方文档不够重视。大家习惯于在入门阶段借助文档完成“快速上手”,却忽视了文档所能够提供给我们的一些更有价值的信息——比如框架的设计思想、源码分层及一些对特殊功能点的介绍。
在专栏的更新过程中,我会在引用官方文档的地方标注出处,这促使了一部分同学去阅读一部分的文档内容,这是一件好事情。React 文档在前端框架文档中属于相当优秀的范本,如果你懂得利用文档,会发现它不只是一个 API 手册或是入门教程,而是一套成体系的官方教学。
如果专栏中的一些文档的摘要引用使你受用,不妨尝试去阅读一下完整的原文。在日常的源码阅读包括生产实践中,如果遇到了 React 相关的问题,请不要急于去阅读参差不齐的社区文章——先问问 React 文档试试看吧,或许你能收获的会比你想象中要多。
若你的学习层次已经超越了阅读官方文档这个阶段,接下来可能会想要了解框架到底是如何运行的。此时你已经掌握了框架的设计理念和基本特性,也有了一些简单项目的实践经验,但或许还并不具备从头挑战源码的知识储备和心理准备。这时,在阅读源码之前,框架的函数调用栈将会给你指明许多方向性的问题。
比如当你想要了解 Hooks,那么就可以尝试去观察不同 Hooks 调用所触发的函数调用栈,从中找出出镜率最高的那些函数,它们大概率暗示着 Hooks 源码的主流程。事件系统、render 过程之类的也是同理。观察调用栈,寻找共性,然后点对点去阅读关键函数的源码,这将大大降低我们阅读源码的难度。
当你理解了一部分核心功能的源码逻辑之后,难免会对整个框架的运行机制产生好奇。这时候直接从入口文件出发去阅读所有的源码,仍然是一个不太明智的选择。
在整体阅读源码之前,我们最好去复习一下框架官方对框架架构设计、源码分层相关的介绍——这些信息未必会全部暴露在文档里,但借助搜索引擎,我们总能找到一些线索——比如框架作者/官方团队的博文,其内容的权威度基本和文档持平。
在理解了整个框架项目的架构分层之后,我们阅读源码的姿势就可以多样化一些了:可以尝试分层阅读,一次搞清楚一个大问题,最后再把整个思路按照架构分层的逻辑组合起来;也可以继续借助调用栈,通过观察一个完整的执行流程(比如 React 的首屏渲染过程)中所涉及的函数,自行将每个层次的逻辑对号入座,然后再向下拆分,我个人采用的就是这种办法。
Git 更像是把数据看作是对小型文件系统的一系列快照。 在 Git 中,每当你提交更新或保存项目状态时,它基本上就会对当时的全部文件创建一个快照并保存这个快照的索引。 为了效率,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。 Git 对待数据更像是一个 快照流。
git保证完整性 (通过计算哈希校验和)
git一般只添加数据
本地执行
已修改
已暂存
已提交
通常有两种获取 Git 项目仓库的方式:
两种方式都会在你的本地机器上得到一个工作就绪的 Git 仓库。
git add 精确地将内容添加到下一次提交中git status -s 精简输出 ?? 新添加的未跟踪的文件A 新添加到暂存区中的文件M 修改过的文件MM 已修,暂存后又作了修改.gitignore 所谓的 glob 模式是指 shell 所使用的简化了的正则表达式。 星号(*)匹配零个或多个任意字符;[abc] 匹配任何一个列在方括号中的字符 (这个例子要么匹配一个 a,要么匹配一个 b,要么匹配一个 c); 问号(?)只匹配一个任意字符;如果在方括号中使用短划线分隔两个字符, 表示所有在这两个字符范围内的都可以匹配(比如 [0-9] 表示匹配所有 0 到 9 的数字)。 使用两个星号()表示匹配任意中间目录,比如 a//z 可以匹配 a/z 、 a/b/z 或 a/b/c/z 等。
# 忽略所有的 .a 文件
*.a
# 但跟踪所有的 lib.a,即便你在前面忽略了 .a 文件
!lib.a
# 只忽略当前目录下的 TODO 文件,而不忽略 subdir/TODO
/TODO
# 忽略任何目录下名为 build 的文件夹
build/
# 忽略 doc/notes.txt,但不忽略 doc/server/arch.txt
doc/*.txt
# 忽略 doc/ 目录及其所有子目录下的 .pdf 文件
doc/**/*.pdf
如果
git status过于简略,想知道具体修改了什么地方,可以用
git diff回答了(git status+ 补丁)
- 当前做的哪些更新尚未暂存?
- 有哪些更新已暂存并准备好下次提交?
- 比较的是工作目录中当前文件和暂存区域快照之间的差异,也就是修改之后还没有暂存起来的变化内容
git diff --staged要查看已暂存的将要添加到下次提交里的内容git diff --cached查看已经暂存起来的变化 (同上)git difftool插件版本
git commit -a 参数跳过git add git rm 从暂存区域移除,然后提交。下一次提交时,该文件就不再纳入版本管理了。 如果要删除之前修改过或已经放到暂存区的文件,则必须使用强制删除选项 -f(译注:即 force 的首字母)。 这是一种安全特性,用于防止误删尚未添加到快照的数据,这样的数据不能被 Git 恢复。
git rm --cached README 我们想把文件从 Git 仓库中删除(亦即从暂存区域移除),但仍然希望保留在当前工作目录中。 换句话说,你想让文件保留在磁盘,但是并不想让 Git 继续跟踪。 当你忘记添加 .gitignore 文件,不小心把一个很大的日志文件或一堆 .a 这样的编译生成文件添加到暂存区时,这一做法尤其有用。
git mv README.md README 相当于:$ mv README.md README
$ git rm README.md
$ git add README
git log不传入任何参数的默认情况下,git log 会按时间先后顺序列出所有的提交,最近的更新排在最上面。 正如你所看到的,这个命令会列出每个提交的 SHA-1 校验和、作者的名字和电子邮件地址、提交时间以及提交说明。
-p 或 --patch它会显示每次提交所引入的差异(按 补丁 的格式输出)。 你也可以限制显示的日志条目数量,例如使用 -2 选项来只显示最近的两次提交
--stat 每次提交的简略统计信息--pretty 这个选项可以使用不同于默认格式的方式展示提交历史。 这个选项有一些内建的子选项供你使用。 比如 oneline 会将每个提交放在一行显示,在浏览大量的提交时非常有用。 另外还有 short,full 和 fuller 选项,它们展示信息的格式基本一致,但是详尽程度不一:$ git log --pretty=oneline
ca82a6dff817ec66f44342007202690a93763949 changed the version number
085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 removed unnecessary test
a11bef06a3f659402fe7563abf99ad00de2209e6 first commit
format 可以定制记录的显示格式$ git log --pretty=format:"%h - %an, %ar : %s"
ca82a6d - Scott Chacon, 6 years ago : changed the version number
085bb3b - Scott Chacon, 6 years ago : removed unnecessary test
a11bef0 - Scott Chacon, 6 years ago : first commit
| 选项 | 说明 |
|---|---|
%H | 提交的完整哈希值 |
%h | 提交的简写哈希值 |
%T | 树的完整哈希值 |
%t | 树的简写哈希值 |
%P | 父提交的完整哈希值 |
%p | 父提交的简写哈希值 |
%an | 作者名字 |
%ae | 作者的电子邮件地址 |
%ad | 作者修订日期(可以用 --date=选项 来定制格式) |
%ar | 作者修订日期,按多久以前的方式显示 |
%cn | 提交者的名字 |
%ce | 提交者的电子邮件地址 |
%cd | 提交日期 |
%cr | 提交日期(距今多长时间) |
%s | 提交说明 |
oneline 或 format 与另一个 log 选项 --graph 结合使用时尤其有用。 这个选项添加了一些 ASCII 字符串来形象地展示你的分支、合并历史:$ git log --pretty=format:"%h %s" --graph
* 2d3acf9 ignore errors from SIGCHLD on trap
* 5e3ee11 Merge branch 'master' of git://github.com/dustin/grit
|\
| * 420eac9 Added a method for getting the current branch.
* | 30e367c timeout code and tests
* | 5a09431 add timeout protection to grit
* | e1193f8 support for heads with slashes in them
|/
* d6016bc require time for xmlschema
* 11d191e Merge branch 'defunkt' into local
| 选项 | 说明 |
|---|---|
-p | 按补丁格式显示每个提交引入的差异。 |
--stat | 显示每次提交的文件修改统计信息。 |
--shortstat | 只显示 --stat 中最后的行数修改添加移除统计。 |
--name-only | 仅在提交信息后显示已修改的文件清单。 |
--name-status | 显示新增、修改、删除的文件清单。 |
--abbrev-commit | 仅显示 SHA-1 校验和所有 40 个字符中的前几个字符。 |
--relative-date | 使用较短的相对时间而不是完整格式显示日期(比如“2 weeks ago”)。 |
--graph | 在日志旁以 ASCII 图形显示分支与合并历史。 |
--pretty | 使用其他格式显示历史提交信息。可用的选项包括 oneline、short、full、fuller 和 format(用来定义自己的格式)。 |
--oneline | --pretty=oneline --abbrev-commit 合用的简写。 |
git log 输出的选项| 选项 | 说明 |
|---|---|
-<n> | 仅显示最近的 n 条提交。 |
--since, --after | 仅显示指定时间之后的提交。 |
--until, --before | 仅显示指定时间之前的提交。 |
--author | 仅显示作者匹配指定字符串的提交。 |
--committer | 仅显示提交者匹配指定字符串的提交。 |
--grep | 仅显示提交说明中包含指定字符串的提交。 |
-S | 仅显示添加或删除内容匹配指定字符串的提交。 |
有时候我们提交完了才发现漏掉了几个文件没有添加,或者提交信息写错了。 此时,可以运行带有 --amend 选项的提交命令来重新提交:
$ git commit --amend
例如,你提交后发现忘记了暂存某些需要的修改,可以像下面这样操作:
$ git commit -m 'initial commit'
$ git add forgotten_file
$ git commit --amend
最终你只会有一个提交——第二次提交将代替第一次提交的结果。
git reset 来取消 git addgit push origin master
只有当你有所克隆服务器的写入权限,并且之前没有人推送过时,这条命令才能生效。 当你和其他人在同一时间克隆,他们先推送到上游然后你再推送到上游,你的推送就会毫无疑问地被拒绝。 你必须先抓取他们的工作并将其合并进你的工作后才能推送
git remote show origin
git tag -a v0.1 -m "my version 0.1" 附注标签
git show 可以看到标签信息和与之对应的提交信息
git tag v0.1-1w 轻量标签本质上是将提交校验和存储到一个文件中——没有保存任何其他信息。
后期打标签
$ git log --pretty=oneline
9fceb02d0ae598e95dc970b74767f19372d61af8 updated rakefile
964f16d36dfccde844893cac5b347e7b3d44abbc commit the todo
8a5cbc430f1a9c3d00faaeffd07798508422908a updated readme
$ git tag -a v0.2 9fceb02
git push origin <tagname> | tags //v0.2 | 多个标签git tag -d <tagname> 并不会作用于远程仓库 需要
git push <remote> :refs/tags/<tagname> :
$ git push origin :refs/tags/v0.2-1w
上面这种操作的含义是,将冒号前面的空值推送到远程标签名,从而高效地删除它。
第二种更直观的删除远程标签的方式是:
$ git push origin --delete <tagname>git checkout 0.2 检出标签git branch testing 创建分支,它只是为你创建了一个可以移动的新的指针git checkout -b <newbranchname> 创建并切换分支git merge <branchname>git branch -d <branchname>git branch --merged | --no-merged 已 | 未 合并的分支git remote add teamone git://git.team1.ourcompany.com 添加远程分支git fetch teamone 抓取远程仓库 teamone 有而本地没有的数据